
OpenAI Just Changed UI/UX Design Forever - The Rise of "Fluid UI"
The latest image model is capable of generating pixel perfect UI mockups. This calls into question whether we should be designing UIs the traditional way (with Figma, Adobe, etc).

OpenAI just released an upgrade for GPT-4o’s image generation feature, 15 months after the release of Dall-E 3, and the Internet is already impressed with its state of the art capabilities.
Notably, the new model is capable of rendering text almost exactly as you prompt it. Plus, it outperforms other models in terms of photorealism, ability to follow complex artistic and camera direction, etc. See this GPT-4o generated image for yourself.

These abilities (e.g. text rendering) make the model tremendously useful for “business design use cases”. Now, marketers can use GPT-4o to generate and edit Youtube thumbnails, Instagram creatives, infographics, banner ads, and many other artifacts that people create with Photoshop and Canva. This was not really possible with Stable Diffusion or Midjourney.
As a result, the TAM (total addressable market) for image models will expand way beyond generating concept arts, design sketches, or NSFW images. It’s bad news for Canva, especially, which sold ease of use. Where Stable Diffusion failed, OpenAI may succeed.
But here’s the really underrated aspect of this release.
It’s that the new model has the ability to generate pixel perfect UI designs on demand. If LLMs can produce UI mockups, it accelerates design and prototyping processes even further, without needing to “vibe code” even.
And this opens the door for LLMs to dynamically generate and personalize UIs for users in run-time, as opposed to being limited to what’s hard coded as HTML/JS/CSS.
Here’s what I mean.
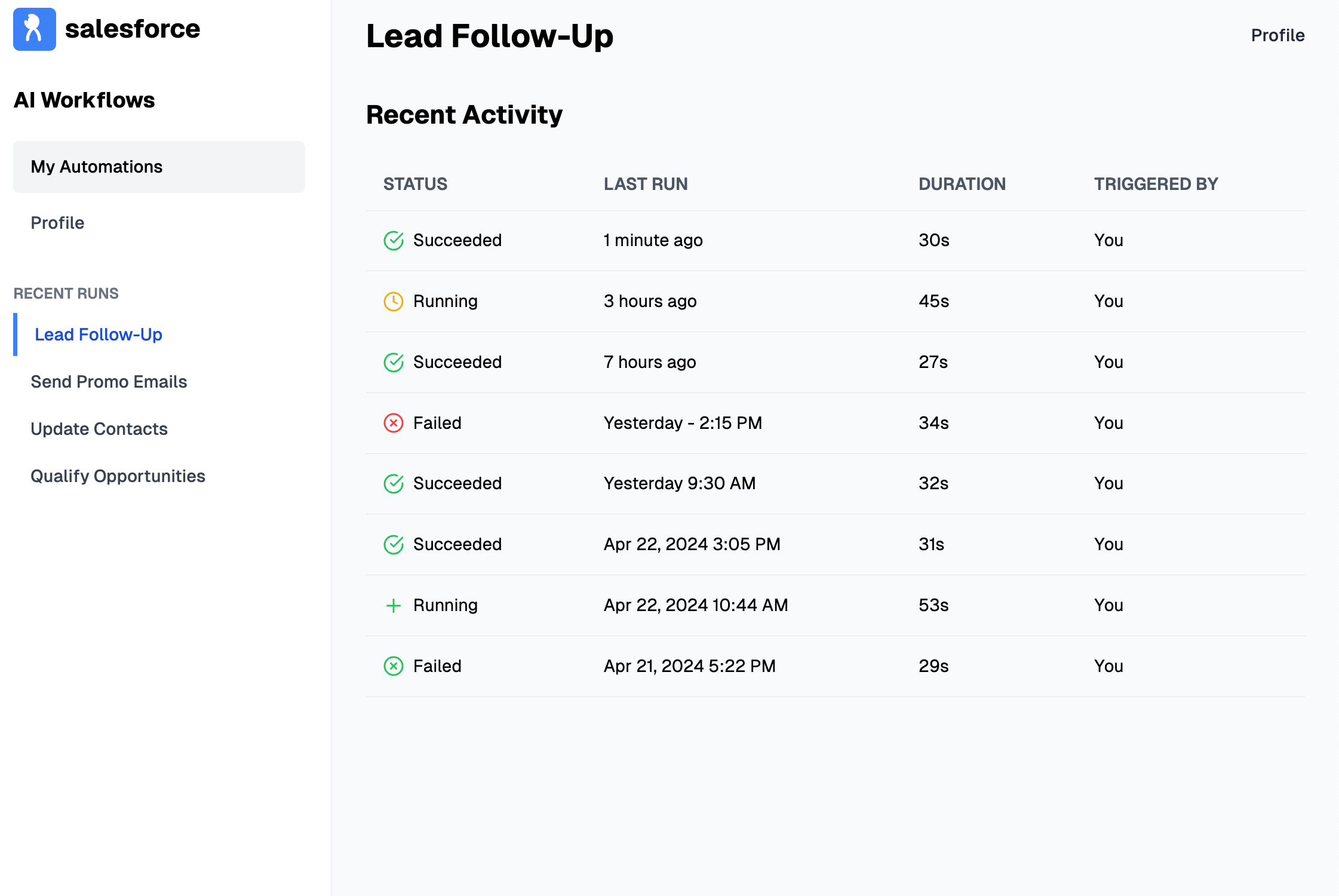
It is well known that people hate using Salesforce, and the UI is ugly and unintuitive. So I asked GPT-4o to do an AI-native redesign of it using this prompt, and here’s what I got.
I want you to create a UI for a SaaS application that's a complete, modern redesign of SalesForce. On the left side bar, it will have "AI workflows", "My Automations", "Profile", then a divider. Below the divider, there will be a set of recent run automations, one of which will be active. On the main content area, there will be a table that shows all the recent runs of the active automation. It will show me status of the run, when it was last run, etc. Create any useful content in it to make it a realistic mock of the UI. Now, instead of writing code, I want you to draw an image of this UI.

What really impressed me was that the model was able to not only render text perfectly, but placed them spatially according to my design requirements (“left navbar”, “divider”, etc).
The design followed the visual hierarchy that I specified (albeit in a half-assed way), and yet it still produced something clean and decent. There is ample room for improvement in prompting that I haven’t even touched upon.
Then, I was interested whether the mock can be “edited” through prompting alone, and maintain consistency. For example, I didn’t want my feedback to completely change the design, like other image models do. To test GPT-4o’s consistent editing capability, I asked it for a “dark mode”.
Great! Add a dark mode toggle next to Profile, and show me what the dark mode of this UI would look like.

Remarkably, the dark mode view was generated, with almost all of the visual elements flipped to dark theme (with some very minor inconsistencies). Text elements stayed the same. The toggle was rendered incorrectly inside the table header, as opposed to what I asked (“next to profile”). But for now, I could live with that.
🚀 I have been working on an AI agent workshop and it has finally materialized. It will be a 5 week, cohort based program, where you will be building AI agents and automation under my guidance and peer support. It’s mean for business owners, PMs, innovators at companies, and consultants to gain confidence with AI agents in 2025.
Unlike most programs online, it will be practical and hands on. No prior programming experience is necessary, although knowledge of prompt engineering, passion for AI, and intuitive understanding of ChatGPT or other AI tools is required.
The first cohort starts on April 23rd, and I am currently accepting applications. For more information, check out this page for more.
Just as a cherry on top, I asked GPT-4o to generate a Tweet announcing this redesign as an image. This tests the model’s ability to not just generate a tweet (which we know it can do), but bake that faithfully into an image. This is a test of multiple things at once.
Ok, now I want you to create an awesome tweet about launching my redesign of Salesforce, but as an image.

The result was the above, which was not quite what I wanted (as I wanted to see the whole tweet container), but it was my fault for not specifying that in the prompt. Still, a solid marketing collateral nonetheless.
Not stopping there, I immediately “vibe coded” the design into a clickable prototype in 20 minutes using Cursor, and the result was this.
I’m designing a workshop on AI agents and automation implementation, with detailed breakdowns of real-world use cases and step-by-step walkthroughs of AI agents. It’s meant for product managers, founders, agencies, and consultants who want practical AI insights. If you’re interested, fill out the form here to get notified!
Takeaway and Implications
So what’s the real takeaway here?
What we just witnessed here is that now ChatGPT - and soon Gemini, etc - is capable of 1) generating many variations of high fidelity designs at scale, and 2) allowing for “natural language”-driven editing.
It’s basically like having a designer right by you, who can produce high fidelity mockups on demand, albeit as images rather than Figma or PSD files.
With just 30 seconds of latency, you can make edits (e.g. “add a modal”). Soon, once GPT-4o API supports image generation, we may be pumping out hundreds of these UI mockups in the background.
Right now, each generation is slow (takes 30 seconds), but undoubtably latency will dramatically improve over the next few months.
This is a really profound change - something people don’t grasp yet - and there will be two main layers of implications stemming from LLM’s ability to produce high quality designs programmatically.
The first ripple effect is obviously that prototyping will soon be done at the speed of thought.
Now, the right way to “vibe code” is not to use Cursor, Loveable, etc, but to just ask GPT-4o for a couple hundred designs based on its knowledge of competitors, and just recommend me the best ones. Your job is to just “vibe judge” the results. Then, you should feed those designs into Claude Code or whatever the tool-du-jour is, and get a semi-working prototype out of that.
This approach is superior to using Cursor or Loveable, etc, in that it’s not stuck in the same cookie cutter “tailwind” aesthetic, which will probably go out of fashion at some point. You probably noticed already that every YCombinator apps look the same these days.
But with GPT-4o, at least, you may get more “out of the box” designs, because it’s not bound by whatever framework the Cursor or Loveable prefers.
Note, I can’t guarantee you will make any money selling apps this way, because you should know by now that app building may be “solved” in the next 1 year or so, and the barrier of entry is collapsing to zero (which makes me scratch my head at most VC investments, but that’s another story).
The Rise of “Fluid UI”
But the second ripple effect is that now LLMs are very close to just generating personalized UIs on the fly. I call UIs dynamically generated LLMs - “Fluid UIs”.
Here’s what I mean.
After all, what is a User Interface? It’s just some pixels that dance according to some logic on the screen. And what is an image? It’s basically pixels. This means we are close to having LLMs directly generate UIs dynamically, as opposed to relying on servers or browsers to render a UI based on fixed rules specified as Javascript code.
So at some point in the next few years, it may be economically feasible to render entire UIs with LLM calls alone, frame by frame. Essentially, we leverage a LLM or image generation model to render UIs as an image or HTML/CSS. We do that for every frame of the UI.
This sounds really inefficient, right? After all, LLM calls are expensive. But this is perfectly reasonable if it means every user can “prompt” the UI to customize it however they want it. Plus, LLM calls are getting cheaper every year.
Since LLMs can maintain consistency, it will be trivial to simulate different variations of button states (e.g. clicked, disabled, etc). Text rendering will be solved also. The LLM will simply generative the UI that the user wants, based on the data that’s in the database.
In this world view, software UIs might become “fluid”, and change dynamically based on “prompts”. This enables infinite personalization and customization. For example, If a user wants all navigation bars to disappear, she may “prompt” the LLM to dynamically re-render a clean UI. She wants the font to change to Comic Sans? That’s easy. Want to change the color scheme to pink? That’s easy, too.
The Future Is Now
The real competitive implication of all this is that design is fast becoming a commodity - and even faster than coding.
Of course, there will still be a market for truly top-notch, innovative design, so I am not doomposting about the designer profession (they should be worried, though. Because soon the only thing standing in between a designer and unemployment might be corporate politics).
But design skills will undoubtably get even more democratized by models like GPT-4o that can render text inside images (and soon videos) with high fidelity.
This is bad news for Canva and other low hurdle design tools that basically just sell design templates. Or any business selling templates in general.
And lastly, the “moat” for software is crumbling really fast. Right now, basically many SaaS companies are just one bold founder away from being undercut to oblivion. But that bold founder will also get undercut, only to be undercut by another founder, etc.
I wrote about this almost 2 years ago in AGI’s impact on tech valuations.