


OpenAI’s Deep Research: The "Big Bang" Event for AI Agents
Do we finally have a killer app for AI agents? What this means for AI and everyone else.

OpenAI just released Deep Research, a new ChatGPT feature that can perform in-depth research by surfing the Internet on its own. To quote an OpenAI researcher, now workers can “hand it a hard problem, grab a coffee, and come back to a well-researched solution in 10–30 minutes.”
The initial reviews range from glowing reviews to skepticism, but I view Deep Research as OpenAI’s most important product release since ChatGPT itself. The product has rough edges as a V1, but Deep Research will be the “killer app” that OpenAI needed to elevate itself into an “AI agent” company, and break free from the competitive chatbot space.
In the process, OpenAI will significantly accelerate AI agent adoption timelines for both B2C and B2B, as the first “agent app” to cross over to mass market. In fact, its coding and other vertical AI agents are rumored to hit in the middle of H1.
Will this help OpenAI’s competitors and AI startups? Maybe. Now, everyone has something concrete to reference when selling AI agents. However, it’s unclear whether Deep Research is bullish for AI startups and existing productivity software. Rather, OpenAI will emerge as a very formidable competitor in the AI applications / agents layer.
Thus, companies will need a crisper answer to: “so how are you better than Deep Research?”, which is harder than “so how is this different from ChatGPT?”.
In the rest of this post, I will dive deeper into Deep Research product, some example use cases, tips, and discuss strategic implications to both B2C and B2B AI agent markets.
![Introduction to Deep Research from OpenAI [LIVESTREAM] - Community - OpenAI Developer Community](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fff8a4d1e-163d-472e-a55b-438da07b0fc0_1280x720.jpeg "Introduction to Deep Research from OpenAI [LIVESTREAM] - Community - OpenAI Developer Community")
What exactly is Deep Research?
Deep Research is an AI agent trained specifically for the long-running research task. A useful mental model is that it is a “graduate level” research assistant that can independently carry on cumbersome Internet research, and compile it into a very in-depth report (10K+ words).
This is vastly different from ChatGPT, which behooves you to drive the conversation. The chat is inert if you stop prompting. But Deep Research can lead itself until it satisfies the goal, and depending on the complexity of task, take an arbitrary long amount of time (typically less than 20 minutes).
Research-focused AI products (e.g. Perplexity) or AI native productivity software (e.g. Hebbia, Glean) aren’t new. But what matters is execution. Deep Research’s simple chat interface belies a mountain of technical breakthroughs, abstracting unnecessary complexity away from the user. It does not suffer any of the UX problems I described in my previous AI agent post, “Why AI agents feel scammy, despite impressive demos”.
But even as V1, the value is unmistakably there. You no longer need to “drive” the search process, or deal with “building AI workflows”. You just say what you need, and can kick off hundreds of these research jobs in parallel, and in the background. This potentially unlocks the path to 100x+ productivity gains.
This saves hours (if not days) of your time and frustration. Why? You no longer need to open 30 browser tabs and read SEO optimized marketing content, to start. It is especially superhuman at researching topics you have little previous experience with. This helps greatly since it eliminates the problem of “not knowing where to start”.
My favorite use case so far is for 1) doing a first-pass deep dives into topics I have no prior knowledge of (most market research falls into this bucket), 2) aggregating the latest news of a domain I’m familiar with (RIP newsletters?), 3) finding valuable info hidden beneath the first page of Google, and 4) researching products for shopping.
Intense People Search: Make a summary of all exec-level AI related hires by publicly traded companies. Great (9/10), Took 14 minutes, cited 40 sources. See full prompt and conversation.
Equity Research: Writing an equity analyst report on AMD (but only using data up to December 2023 - “as of”). Overall decent (7/10). Took 8 minutes, 30 sources. See full prompt and conversation.
Current News Summary: Assess the market and fan reactions for the Luka Doncic and Anthony Davis trade, and summarize the impact. Did great (10/10), produced something better than anything I read on this. Took 6 minutes, cited 25 sources. See the full prompt and conversation.
There was a twitter thread that said Deep Research hallucinates on these types of tasks but I suspect the poster didn’t know you could “tell” Deep Research to only consider sources after a certain date.
Shopping Task: Buying the best bicycle that meets a lot of random criteria under $300. Overall good (8/10), took 12 minutes, cited 20 sources. See full prompt and conversation
More examples which I will share to my subscribers separately by next week.
Deep Research also excels at producing citations, although there’s room for improvement in terms of upping the quality and volume of citations (which are fixable problems).
What I like: it often quoted content that’s buried 10 pages down in Google search results, as well as PDFs. The citations were also not just links but highlighted sections within documents. This shows that Deep Research indeed does “deep reading”, and not just shallow summaires of top ranked results like Google’s AI Overviews.
But seeing Deep Research as just a mere time-saver is the wrong perspective. Right now, each Deep Research query is about $1.8 ($200/month pro tier gets 100 queries, minus the $20 plus tier sub). This means anyone who is paid to do research at a higher rate can linearly multiply her productivity by spinning tens, if not hundreds, of these agents in the background.
We are talking 100x productivity gains, not saving merely 4 hours a day. Whether Deep Research’s output meet your “bar” will highly depend on your job function (mileage may vary). But this is overall bullish for agent driven AI consumption. Also, OpenAI basically proved AI automation can be done with plain english, without the Rube-Goldberg machines of AI workflows.
Also, Deep Research opens a new paradigm of AI consumption. It’s “goal-driven”, not “prompt” or “query” driven. You ask it what you want, and you either get the result, or may be asked (by the AI) some clarifying questions. If the agent gets stuck, you may be asked to prod it in the right direction.
This mirrors basically how we interact with human coworkers. And yes, Deep Research isn’t the first product to do this, but it is the first product that’s worth respecting as a coworker.
Worth the money?
So is Deep Research worth the money? It depends basically on how much you value your time. But we can also draft quantitative proofs on why a single Deep Research query is worth more than $2.
Take the e-commerce use case, for example. If I am shopping for a new bicycle or a new Motorboat - things I know little about - then asking Deep Research is far more enjoyable than opening 20 browser tabs, reading affiliate link-spam. If I just save $2 with Deep Research, it paid for itself.
Stock pitch use case is another clear winner. This works for stocks you are familiar with, or the ones you know nothing about. The clear advantage of Deep Research - aside from the depth - is that it provides multiple perspectives gleaned from the sources (both bullish and bearish cases).
So reading Deep Research is basically cherry picking the best ideas from a bunch of articles. Clearly this is worth more than $2 per report, especially if you are managing millions. The quality seems good to me (as a former Wall Street trader).
What about for coding? Much of senior engineering leaders’ role is to have a good grasp of technical landscape. Deep Research makes it fairly trivial to just ask for an industry report on the fly (e.g. “the top 10 telemetry vendors with publicly available pricing, outputted in a table format, ranked by recent developer momentum”, “top recent trends in AI infrastructure tooling space”).
Basically, it’s your personalized Gartner report generator. Obviously, this will impact how tech sales is done - the buying journeys will start from ChatGPT increasingly. Do we really need to pay $300K for SAs to explain 10% of what Deep Research can say?
Can DeepSeek Copy This?
So how long will it take for DeepSeek and others to roll their own Deep Research?
After Deep Research’s release, many “open source” projects have been published, such as HuggingFace’s Open-Deep Research, and so on. There’s even Google’s Deep Research (same name), released in December 2024. But fundamentally, these projects are built on a different (and inferior) tech foundation compared to OpenAI’s Deep Research.
Why? The heart of Deep Research is a purpose-built (fine-tuned) version of the unreleased O3 model (the one that broke the ARC-AGI benchmark), augmented with Internet browsing and coding capabilities.
This also means Deep Research uses a reasoning model that “figured out” how to use tools (like a browser), but also stay “focused on task” over a very long timespan. In other words, OpenAI cured LLMs of ADHD over long horizons. This was always the big challenge when building AI agents.
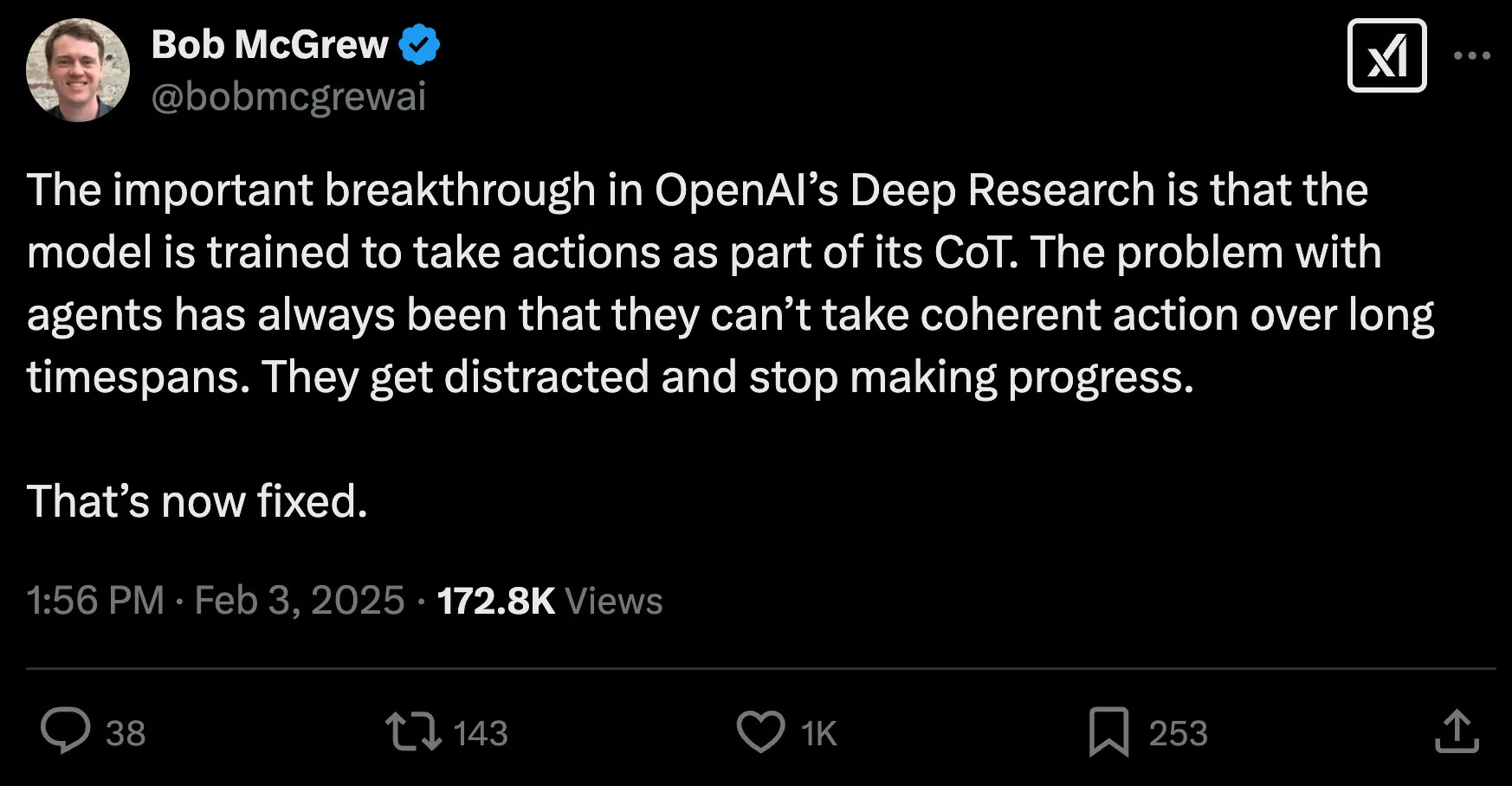
This means there’s at least three hurdles for competitors to overcome:
Replicating the O3 model performance itself (note: DeepSeek R1 is slightly below O1 model), then figure out how to finetune it for the research task.
Building a fast retrieval system of documents that works across the entire Internet in real time.
Figuring out how to not hallucinate even when generating over millions of tokens in context.
It’s unclear how much OpenAI spent to finetune Deep Research model (or train O3). So clearly capital could be a barrier of entry. Training data presents another barrier. Algorithmically speaking, there’s less uncertainty. The following quote from OpenAI indicates that reinforcement learning is heavily utilized, although the wording is profound but vague, and certainly not informative enough to do any direct replication.
Trained end-to-end with reinforcement learning in a tool-enabled environment, deep-research is built to seek truth and understand the universe.
Clearly, it’s impossible to prevent trade secrets from diffusing to competitors, so I expect OpenAI to be much more aggressive in building a “product” with real stickiness around Deep Research. This means it’s unclear if OpenAI ever releases an API version of Deep Research (although, O3 will be available as an API).
Enterprise Impact
In the announcement post for Deep Research, there’s a very interesting bit:
… The model is also able to browse over user uploaded files, plot and iterate on graphs using the python tool, embed both generated graphs and images from websites in its responses
This suggests that Deep Research’s scope isn’t limited web search, but extends to Enterprise Search markets as well - at the least. Basically, the foundation of every AI startup so far has been RAG (retrieval augmented generation). So if OpenAI just discovered a better way to understand large amounts of data, then there will be considerable ripple effects.
In my previous post titled “OpenAI’s biggest worry isn’t DeepSeek”, I argued that OpenAI already shifted to being a product company, precisely because Sam Altman realized 18 months ago that just competing in the model layer has no moat (among other reasons).
And for OpenAI, the real “product” may be AI agents, not the chat interface.
Chat maybe just user interface, but not the end state. Deep Research confirms that OpenAI will confirm heavily in the application layer, armed with best in class models. It’s unclear if OpenAI will use Deep Research (and the tech behind it) to drive adoption to premium tiers of ChatGPT and ChatGPT enterprise only.
The low hanging fruits for OpenAI may be entering the $10 Bn enterprise knowledge management market (e.g. Glean, which is at $100M ARR). I also expect significant continued headwind for specialized vector database companies if RAG turns out to be an obsolete paradigm for building research agents.
Also, while I see OpenAI really popularizing AI agents for consumers, I don’t see this necessarily as a long term positive for startups. General purpose AI agents powered by the frontier models will always outperform specialized AI agents sold by startups. In the short term, Deep Research’s success may help AI agents speed up their sales cycles. Personally, I will bet on general purpose AI agents winning every market, but that’s the subject of another post.
There’s significant momentum for OpenAI’s premium subscriptions (16M for Plus tier, ~150K for Pro tier), as well as Enterprise (~800M-1Bn in ARR), which already amount to about $5bn+ in ARR already.
This already makes ChatGPT a top 5 productivity software company in the world, except it’s growing at triple digit rate. Outside of tech circles, DeepSeek or Llama are virtually unknown, so the recent DeepSeek media cycle probably had negligible impact on churn for ChatGPT.
Conclusion
Sam Altman sees Deep Research potentially doing single digit percentage of all knowledge work.
Assuming that’s true, this statement can be interpreted in two ways:
we can do more of that automate-able work, million times more efficiently with AI, or
whoever’s doing that work will be replaced by AI
I think the future is somewhere in between, or both can happen. I am working on a broader job market impact essay, so subscribe to stay updated.